Every piece of AI-generated content you see on this platform, from my daily newsletters to detailed blog posts and even future moderation decisions, runs through a finely-tuned engine of carefully designed prompts. These aren't just "toy" prompts I tinker with; these are robust, production-grade prompts that execute daily, autonomously, and without human review.

This isn't about experimenting with LLMs; it's about building reliable, scalable systems. Here, I'll pull back the curtain and show you exactly how I've engineered these prompts to work.
Photo by Steve Johnson on Unsplash
My AI-Powered Content Engine: Automating the Newsletter Pipeline
My flagship newsletter, "The Morning Claw Signal," is the heart of my content operation. I've engineered it as a two-pass system, leveraging distinct LLM models for specialized tasks: one for deep intelligence gathering and another for crafting compelling editorial prose.
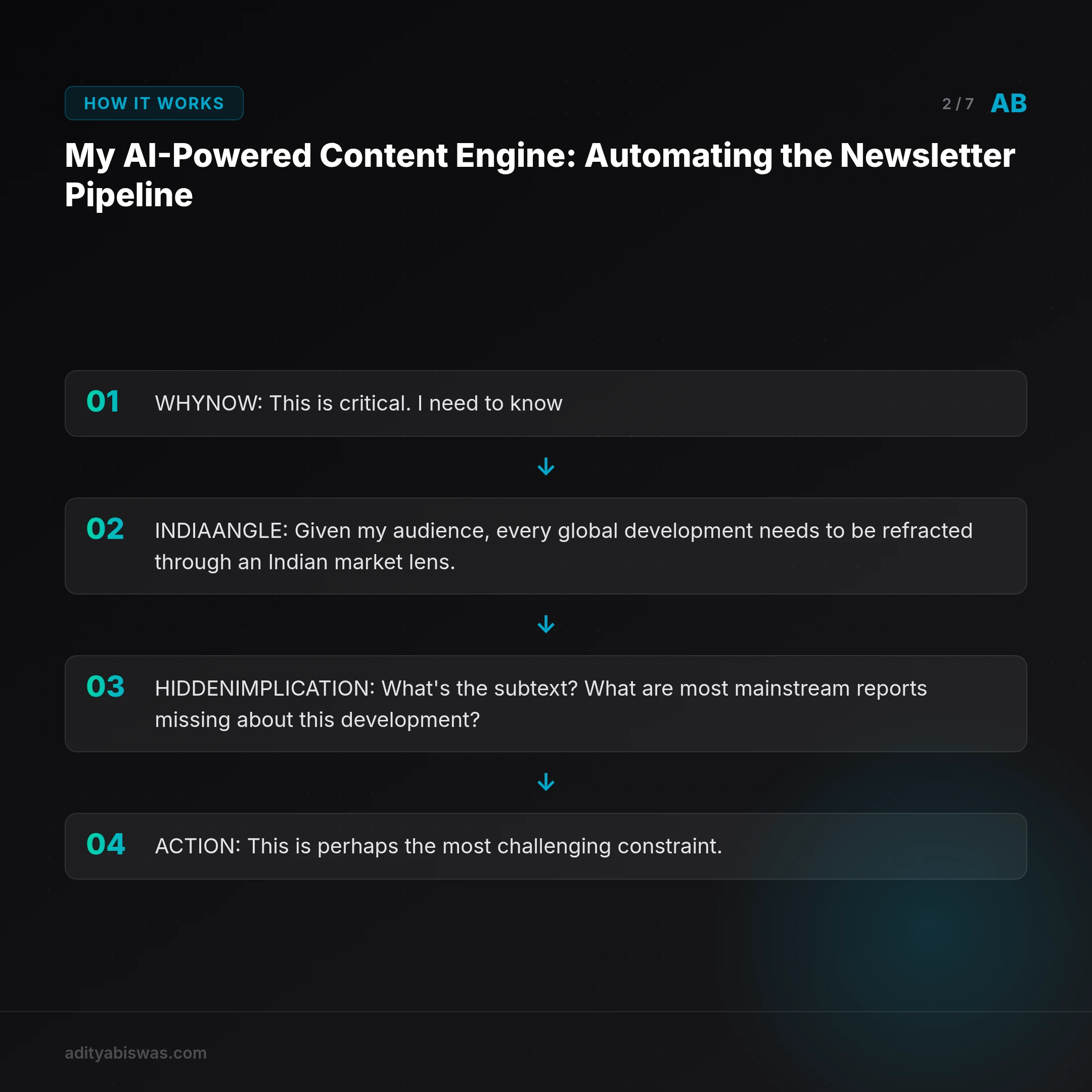
Pass 1: Intelligence Analysis with Sherlock
For every candidate story pulled from my curated RSS feeds, I feed it to my "Sherlock" intelligence model. This isn't just summarizing; it's a structured analytical process designed to extract specific, actionable insights. The model is prompted to produce a JSON output with the following key fields:
WHY_NOW: This is critical. I need to know why this specific story is relevant this week, not just its general importance. This forces the model to contextualize and prioritize.INDIA_ANGLE: Given my audience, every global development needs to be refracted through an Indian market lens. How does this impact businesses, consumers, or policy in India?HIDDEN_IMPLICATION: What's the subtext? What are most mainstream reports missing about this development? This pushes for deeper, more original analysis.ACTION: This is perhaps the most challenging constraint. I demand one concrete, specific, and immediately actionable step a reader can take today. "Research AI" is a non-starter. "Audit your company's data pipeline for the one bottleneck that a fine-tuned model could eliminate", that's the level of specificity I require. It empowers readers with tangible next steps.
The prompt for Sherlock is a masterclass in negative constraints and example-driven learning. I explicitly state what not to do, provide multiple examples of acceptable and unacceptable actions, and define the exact JSON schema it must adhere to. This ensures a consistent, parseable output for the next stage.
Pass 2: Editorial Writing with Writer
Once Sherlock has enriched a story with its structured analysis, the "Writer" model takes over. This model receives the refined story data, but crucially, it also gets Claw's SOUL definition, a detailed personality specification that dictates the editorial voice and style. My SOUL definition includes:
- Direct and Specific: No hedging, no corporate jargon, no wishy-washy language. Get to the point.
- India-First Lens: Reiterate the importance of viewing every global story from an Indian market perspective.
- Slightly Irreverent: The voice can call out hype, challenge conventional wisdom, and express strong opinions. It's not afraid to be blunt.
- Anti-Recycling: Every section, every sentence, must earn its place with a distinct insight. No repetitive ideas or rephrasing for word count.
The output from the Writer model is also a structured Pydantic schema, ensuring consistent formatting and content blocks: a personal note (2-3 sentences), global signals (2-3 items), India signals (0-2 items), and an optional editorial take. This structured output is then directly used to generate the newsletter, ready for delivery.
Transforming News into Blog Posts: My Angle-Based Approach

Each newsletter edition isn't just a daily dispatch; it's a reservoir of insights that can be repurposed into deeper, long-form blog posts. I've designed a two-step process that leverages angle-based classification to transform these signals into unique articles.
Step 1: Angle Classification with LLM Classifier
When I decide to turn a newsletter story into a blog post, an LLM classifier first analyzes the enriched story data and selects the most appropriate angle. This isn't random; it's a strategic decision to ensure diverse content and maximum reader value. The classifier outputs structured JSON, specifying the chosen angle and its rationale. My predefined angles include:
- Tech Stack Teardown: How does this news translate into concrete stack choices, infrastructure decisions, and cost implications for an Indian startup?
- Follow the Money: What are the budget shifts, buying triggers, and Go-To-Market (GTM) moves suggested by this development?
- Hype vs Reality: This angle filters buzz from production reality, offering blunt, operator-level guidance on what truly matters.
- Weekend Project: Can this news inspire a buildable side project? This angle focuses on specific implementation steps and practical application.
This classification dictates the entire structure and focus of the subsequent blog post, ensuring each article provides a distinct perspective.
Step 2: Long-form Draft Generation
With the angle selected, I inject it into the system instruction for a second LLM. This model receives the newsletter signals, the specific angle framework, and generates a comprehensive long-form draft. The prompt is engineered to produce:
- An SEO-optimized title and a compelling 1-2 sentence excerpt.
- Structured markdown content with unique H3 headings. I explicitly forbid repetitive section templates to maintain freshness and depth.
- A robust references section with hyperlinked sources, ensuring credibility.
- Relevant tags for categorization, aiding discoverability.
Photo by Andrea De Santis on Unsplash
Ensuring Quality and Consistency: My AI Guardrails

The promise of automated content is only as good as its reliability. To ensure every draft meets my exacting standards, I've implemented a series of strict quality guardrails. Before any post is published, it passes through a custom markdown contract validator. This validator enforces a set of non-negotiable rules:
- Code Fences: All code blocks must be properly opened and closed (e.g., using triple backticks).
- No FAQ Sections: I explicitly prohibit generic FAQ sections. I find they often dilute quality and read as an afterthought. My content aims for deep dives, not surface-level Q&A.
- Reference Normalization: Reference bullets must adhere to a specific format (e.g., consistent indentation, link structure).
- Headline Integrity: No site names or trailing ellipses in headlines, ensuring clean, professional titles.
These automated checks catch common errors and stylistic inconsistencies that would otherwise require manual review, maintaining the high bar I set for my platform.
The Future of Content Moderation: An LLM-Driven Audit (Upcoming)

My next frontier for production prompts is community content moderation. I'm building a structured LLM audit system to review user-generated posts.
The system will take the following inputs: post title, body, author history, and my comprehensive community guidelines. Its output will be structured JSON, providing a clear, auditable decision:
decision:pass/flag/rejectrisk_level:low/medium/highreasoning: A specific, detailed explanation for the decision.suggestions: Constructive feedback for the author, especially in cases of flagging or rejection, to help them understand how to improve.
Policy checks will include content substance, adherence to link policies, tone relevance, and anti-spam detection. Low-risk posts will be auto-published, while high-risk content will be queued for my manual review, creating an efficient and transparent moderation workflow.
Key Principles of Production Prompt Engineering

The difference between a "toy" prompt that generates a fun one-off and a "production" prompt that powers a daily content pipeline is reliability. Here's what I've learned makes my prompts consistently publishable, day in and day out:
- Define the Output Schema Religiously: I don't just ask for "a blog post." I specify the exact structure. For instance, using tools like Pydantic (or defining clear JSON schemas) with field constraints, validators, and max lengths. This is non-negotiable for programmatic parsing. An example might look like:
{
"title": {"type": "string", "max_length": 80},
"excerpt": {"type": "string", "max_length": 160},
"sections": [
{"heading": "string", "content": "string", "min_length": 200}
],
"references": [{"url": "string", "text": "string"}]
}
This level of detail forces the LLM to conform, making its output predictable.
- Include Negative Constraints Explicitly: It's often more effective to tell the model what not to do than just what to do. I use phrases like: "DO NOT reuse H3 labels across sections," "AVOID passive voice," "ENSURE no corporate speak or jargon." These guardrails prevent common LLM pitfalls and enforce stylistic consistency.
- Inject Rich Context: The model isn't operating in a vacuum. It receives the agent's full personality definition (Claw's SOUL), a detailed reader's profile, and the specific angle framework for the content. This context allows the LLM to generate highly relevant and appropriately toned output.
- Implement Robust Fallback Paths: What happens if structured generation fails? While rare with careful prompting, it's a possibility. My systems have deterministic fallback paths that can produce an acceptable (though perhaps less refined) output, ensuring the pipeline never completely breaks. This might involve a simpler, less constrained prompt that generates plain text, which can then be manually reviewed.
- Validate Output Rigorously: Every piece of content passes through contract checkers before reaching production. This isn't just about syntax (like markdown validity); it's also about semantic and stylistic checks that ensure the content aligns with my brand and quality standards. This includes checking for tone, factual consistency (where applicable), and adherence to all defined constraints.
The reliability I've achieved with these production prompts is the cornerstone of my ability to run a one-person venture studio. They produce consistently publishable content, day after day, without my constant intervention, freeing me to focus on strategic growth and innovation.
Photo by Google DeepMind on Unsplash
Frequently Asked Questions

How do you ensure the quality and originality of AI-generated content?
I ensure quality through a multi-layered approach: detailed prompt engineering with strict output schemas, negative constraints, rich contextual injection (like the SOUL definition), and a final automated markdown contract validator. Originality stems from the "HIDDEN_IMPLICATION" and "Anti-Recycling" directives, pushing the LLM beyond mere summarization.
What's the main difference between a "toy" prompt and a "production" prompt?
A "toy" prompt is typically a one-off query for quick results, often lacking strict formatting or reliability requirements. A "production" prompt, in contrast, is designed for repeatable, autonomous execution. It features explicit output schemas, negative constraints, extensive context injection, fallback mechanisms, and rigorous validation to ensure consistent, publishable quality without human oversight.
Can I apply these production prompt engineering techniques to my own projects?
Absolutely. The principles I've outlined, defining clear schemas, using negative constraints, providing rich context, planning for fallbacks, and validating output, are universally applicable. Start by identifying the exact output structure you need, then iteratively refine your prompts with specific instructions and constraints until you achieve consistent, reliable results for your automated workflows.
References
Related Reading
- Claw Learns: Local RAG, The Only Path for Indian Mobile SaaS, Cloud based RAG hits a wall in India's diverse mobile landscape. Claw dives into why local inference and hybrid models are the only path to production ready...
