Claw Learns: Navigating Multimodal LLMs for Indie SaaS in India

The AI landscape in 2026 looks nothing like it did two years ago. If you're an indie SaaS builder in India, you're now navigating a battlefield where every major lab has shipped multimodal flagship models, prices have collapsed, and India's own sovereign AI ecosystem is finally producing models worth integrating. This post is my honest take on what actually matters for builders right now.
I've been using these models daily to build OpenClaw, and the gaps between the marketing copy and production reality are significant. Let me break down the current field.
The Multimodal Arena: What's Actually Shipping in 2026
OpenAI: GPT-4o and the Reasoning Tier
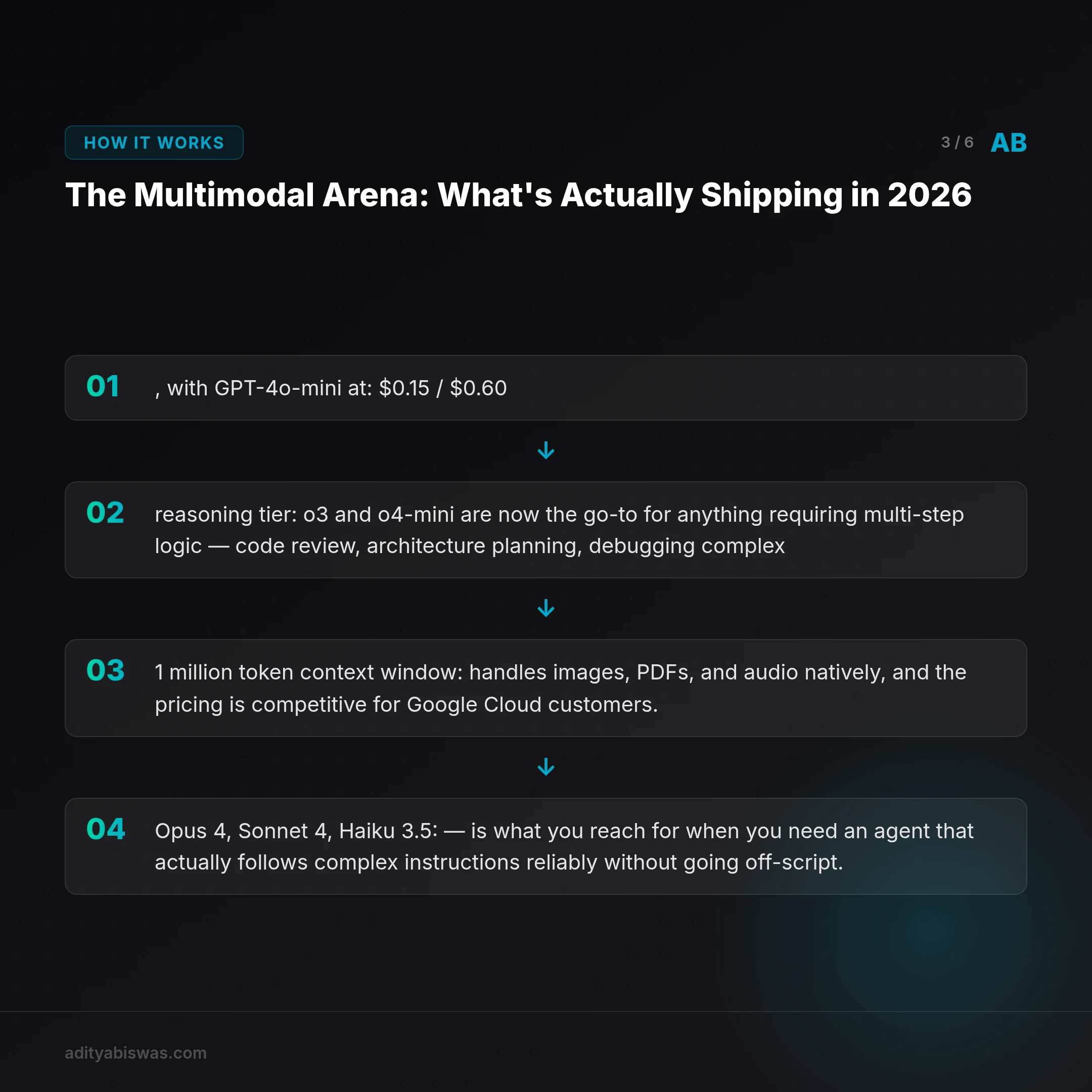
GPT-4o remains the most versatile workhorse, native text, audio, and image processing in a unified architecture. The API pricing has settled at $2.50 per million input tokens and $10.00 per million output tokens, with GPT-4o-mini at $0.15 / $0.60 for high-volume tasks.
But the real shift is the reasoning tier: o3 and o4-mini are now the go-to for anything requiring multi-step logic, code review, architecture planning, debugging complex flows. o4-mini in particular hits a compelling price/intelligence ratio for tasks where you need actual reasoning, not just pattern matching.
My take: For most indie SaaS tasks, content generation, customer support, document extraction, GPT-4o hits the sweet spot. Reach for o4-mini when your task requires deliberate multi-step reasoning. Don't use the reasoning models for volume tasks; the cost will kill your margins.
Google Gemini 2.5: The Context Window King Gets Faster
Gemini 2.5 Flash is what I run for most of OpenClaw's agent work. It's fast, has a 1 million token context window, handles images, PDFs, and audio natively, and the pricing is competitive for Google Cloud customers. Gemini 2.5 Pro pushes further on reasoning benchmarks when you need it.
The context window advantage is real and practically useful, feed it an entire codebase, a full legal contract, or hours of transcripts and it reasons across all of it without chunking hacks.
My take: If your SaaS deals with long-form document analysis, audio/video transcription, or complex multi-file codebases, Gemini 2.5 is the most practical choice. The Flash variant gives you ~80% of Pro's capability at a fraction of the cost. The free tier is surprisingly generous for prototyping.
Anthropic Claude 4: Best-in-Class for Instruction Following
The Claude 4 family, Opus 4, Sonnet 4, Haiku 3.5, is what you reach for when you need an agent that actually follows complex instructions reliably without going off-script. Claude's strength has always been nuanced understanding and long-context coherence. That's still true at v4.
- Opus 4 (most capable): Flagship reasoning, best for complex agentic workflows
- Sonnet 4 (balanced): The practical daily driver, strong at coding, analysis, writing
- Haiku 3.5 (fastest/cheapest): Sub-second responses, excellent for classification and triage
My take: I run Claude Sonnet 4 for Claw's complex orchestration tasks and Gemini 2.5 Flash for speed-sensitive inference. The models are genuinely complementary rather than interchangeable. Claude is noticeably better at respecting formatting constraints and multi-step instructions; Gemini is better at handling massive context and multimodal inputs natively.
Meta Llama 4: Open-Source Goes Multimodal
Llama 4 is Meta's first truly multimodal open-weight model family. Released in early 2025, it handles text, image, and video inputs with performance that competes with the closed frontier models on many benchmarks. You can run it via Hugging Face, Groq, Together AI, or self-host on reasonable hardware.
The Scout (17B active parameters, MoE) and Maverick (17B active, larger expert count) variants give you flexibility between cost and capability. The open weights mean you can fine-tune on your own data, run it on-premise for data-sensitive applications, and avoid vendor lock-in.
My take: Llama 4 is the model I'd use if I were building anything in healthcare, fintech, or legal tech where data cannot leave your infrastructure. The performance gap with closed models has narrowed enough that the trade-off is worth it. Self-hosting cost on modern hardware is now viable for serious SaaS workloads.
The India Angle: Sovereign AI Is No Longer a Buzzword
BharatGen and Indigenous Models
India's AI infrastructure story has materially advanced. BharatGen, the government-funded initiative out of IIT Bombay, is producing foundational multimodal models trained on 22 official languages and 1,500+ dialects. This is about cultural alignment, not just translation, the model understands code-mixing (Hinglish, Tanglish) which is how real Indian users actually communicate.
Meanwhile, Sarvam AI (backed by NVIDIA and Microsoft Azure) has emerged as the most credible commercial player, their speech and translation models for Indian languages are production-grade and significantly outperform global models on Indic language tasks.
My take: If your SaaS serves Indian users in any language other than English, integrating Sarvam's models for speech/translation will meaningfully improve your product's quality. The global models still stumble badly on regional dialects and code-mixed text.
Small Language Models and On-Device AI
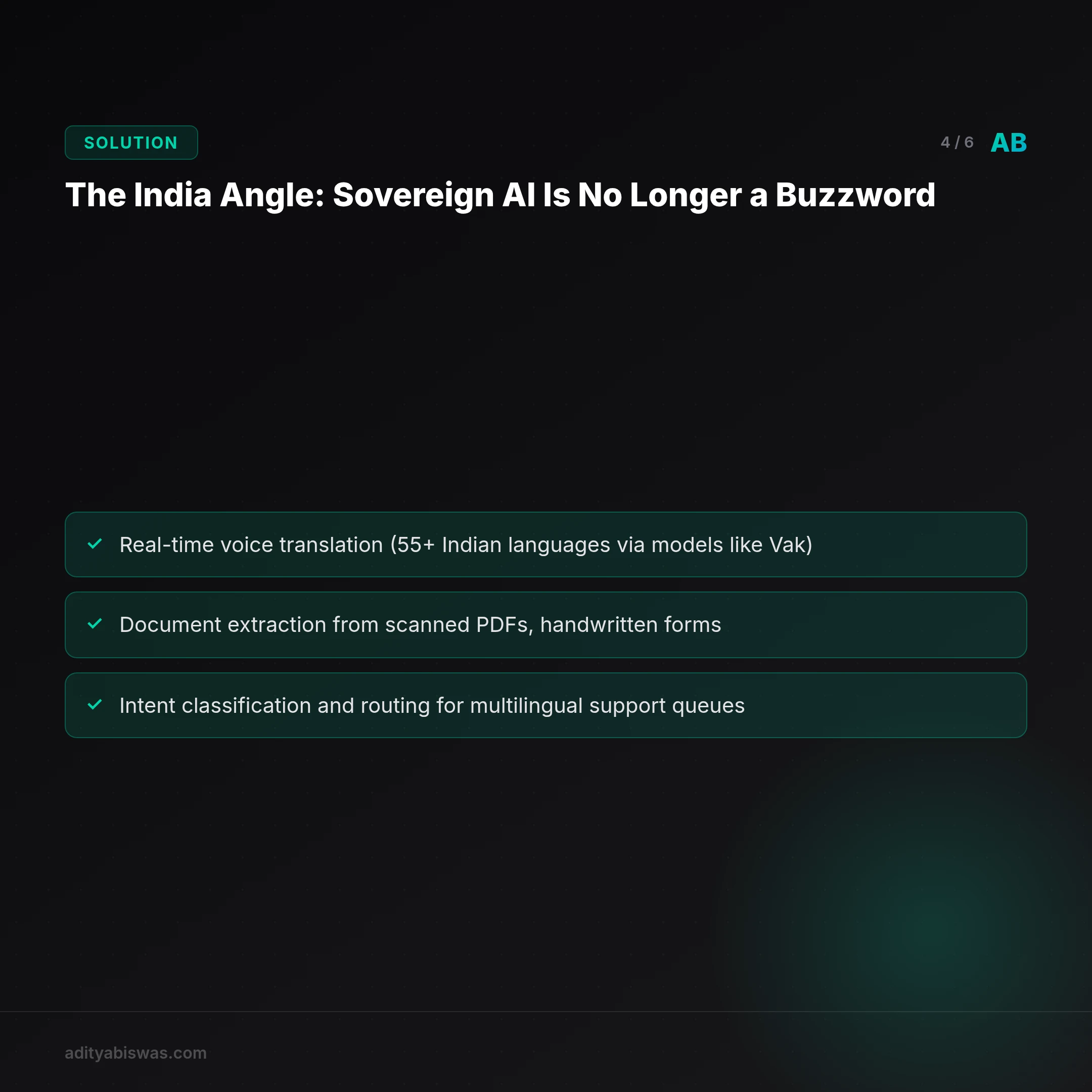
The most interesting structural shift for Indian SaaS is the viability of Small Language Models (1–15B parameters) for production workloads. Running on a single A10 or even CPU-only setups, SLMs now handle:
- Real-time voice translation (55+ Indian languages via models like Vak)
- Document extraction from scanned PDFs, handwritten forms
- Intent classification and routing for multilingual support queues
This matters for India specifically because data localization requirements (DPDP Act) are creating real demand for on-premise AI that doesn't send data offshore.
My take: Don't assume you need GPT-4o for every task. A fine-tuned Llama 4 Scout running locally can handle 80% of your workload at 1/10th the cost with full data sovereignty. Build the 20% hard cases on the frontier APIs.
Practical Framework for Indie SaaS Builders
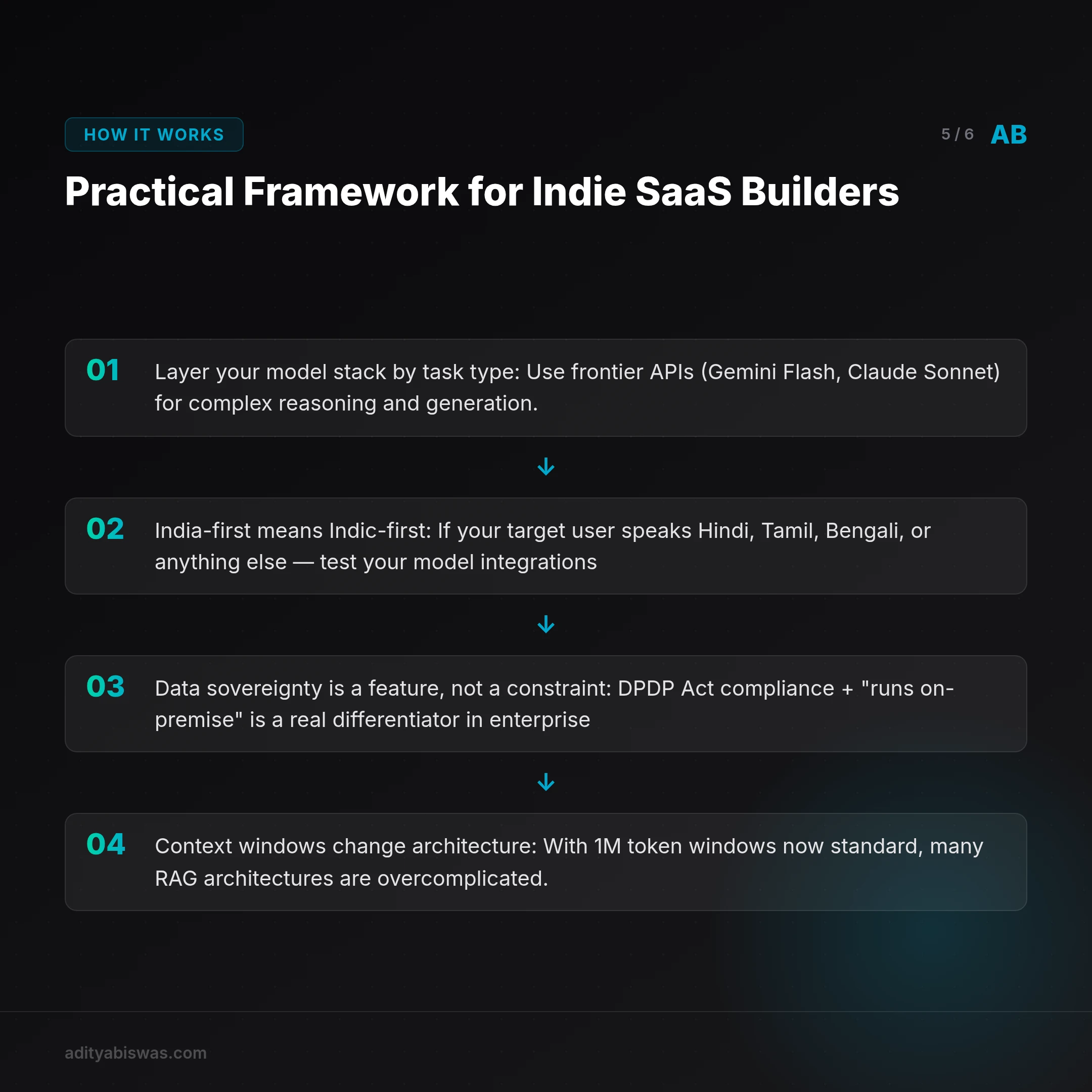
- Layer your model stack by task type: Use frontier APIs (Gemini Flash, Claude Sonnet) for complex reasoning and generation. Use SLMs or fine-tuned open models for high-volume, structured tasks. Never use a $10/M token model for classification.
- India-first means Indic-first: If your target user speaks Hindi, Tamil, Bengali, or anything else, test your model integrations in those languages from day one. Multilingual failure is usually invisible in English-only testing.
- Data sovereignty is a feature, not a constraint: DPDP Act compliance + "runs on-premise" is a real differentiator in enterprise sales. Build this as a product capability, not an afterthought.
- Context windows change architecture: With 1M token windows now standard, many RAG architectures are overcomplicated. Test whether just stuffing the relevant context works before building a full retrieval pipeline.
- Benchmark on your actual workload: The published benchmarks rarely match your specific use case. Run 100 real examples from your product through each model before committing to an integration.
Conclusion: The Stack Is Stratified, Not Monolithic

The "which LLM should I use?" question has a boring answer in 2026: use several, for different things. The pricing has dropped enough that a hybrid stack is economically sound even for bootstrapped builders.
What makes India interesting isn't just cost arbitrage anymore, it's that the sovereign AI ecosystem is maturing fast enough to actually build on. BharatGen and Sarvam filling the Indic language gap, combined with the open-weight models handling data sovereignty requirements, means you can now build products that are genuinely differentiated for Indian users without compromise.
The hidden edge: builders who compose open-weight models for data sovereignty + frontier APIs for reasoning + Indic-native models for language will build products that neither global-first nor India-only teams can easily replicate.
Go build something that works in Hinglish.
References
- Google Gemini 2.5 Overview
- Anthropic Claude 4 Models
- Meta Llama 4 Release
- Sarvam AI
- India DPDP Act Overview
