For the last few months, my feed has been a relentless firehose of "vector databases." Every VC, every AI influencer, and every SaaS company is suddenly an expert on Pinecone, Weaviate, or Chroma. It feels like the early days of "Big Data" all over again, a hyped-up solution in search of a problem.
My default setting is skepticism. I've seen enough tech waves promise a revolution and deliver a slightly better dashboard. But this one felt different. The claims were specific: build apps that understand user intent, not just keywords. So I blocked out a week, brewed some dangerously strong coffee, and went down the rabbit hole.
What I found was that everyone is focusing on the wrong thing. Admiring the vector database is like admiring the bookshelf instead of reading the books. The real story isn't the storage; it's how we translate messy, human concepts into cold, hard math. The database is just the enabler. The embedding model is the magic.
Photo by Luke Chesser on Unsplash
Why Keyword Search is Broken (And How Semantic Search Fixes It)
My starting point was a simple, selfish problem: I want to search my own newsletter archive. Not with Ctrl+F, but by asking a question. If I ask, "What did I write about AI infra costs?" I want to find the post where I discussed "the brutal price of GPU inference," even if the exact phrase "AI infra costs" never appeared.
A traditional database using a LIKE '%infra costs%' query is useless here. It's a glorified string-matcher. It has zero understanding that "costs," "price," and "budget" are related. It doesn't know that "GPU inference" is a core component of "AI infra."
This is the failure of keyword search. It's lexical, not conceptual.
Semantic search fixes this. The core idea is to stop treating words as strings and start treating them as points in a high-dimensional conceptual space. In this space, proximity equals relevance.
The Real Magic: How Embeddings Understand Meaning

This is the part everyone glosses over, but it's the entire foundation. You take a piece of text, a sentence, a paragraph, a whole document, and feed it into a specialized neural network called an embedding model.
From Words to Vectors
The model's sole job is to read the text and output a list of numbers, called a vector. For a popular, lightweight model like sentence-transformers/all-MiniLM-L6-v2, this vector has 384 dimensions (a list of 384 floating-point numbers).
Think of it as a cartographer for concepts. The embedding model draws a giant, multi-dimensional map and places related ideas near each other.
- The vector for "king" will be mathematically close to the vector for "queen."
- The vector for "Bangalore traffic" will be close to "gridlock on Outer Ring Road."
- The vector for "how to invest in stocks" will be near "building a portfolio for beginners."
This numerical representation of meaning is called an embedding.
A Practical Example with Python
Getting started with this is surprisingly simple using open-source libraries. I used sentence-transformers to see it in action. It's as simple as installing the library (pip install -U sentence-transformers) and running a few lines of code.
from sentence_transformers import SentenceTransformer
# 1. Load a pre-trained model from Hugging Face
# This model is great for general-purpose English text and runs on a CPU.
model = SentenceTransformer('all-MiniLM-L6-v2')
# 2. Define the sentences to embed
sentences = [
"The cost of running AI models in production is high.",
"Startups are struggling with GPU inference budgets.",
"India's tech ecosystem is booming in Bangalore."
]
# 3. Generate the embeddings
# The model converts each sentence into a 384-dimensional vector.
embeddings = model.encode(sentences)
# Let's inspect the output
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding Shape:", embedding.shape) # This will print (384,)
print("-" * 20)Running this code gives you a (384,) NumPy array for each sentence. You've successfully converted abstract meaning into a mathematical object that a computer can work with.
Photo by Myriam Jessier on Unsplash
The Scaling Problem: Where Vector Databases Are Necessary
Okay, so I have a vector for my query ("AI infra costs") and a vector for every paragraph in my newsletter. How do I find the most relevant ones?
The simple answer is vector similarity. You calculate the mathematical "distance" between the query vector and all the other vectors in your archive. The ones with the smallest distance (the "nearest neighbors") are the most semantically similar. A common metric for this is Cosine Similarity, which measures the angle between two vectors. A smaller angle means they're pointing in a similar "conceptual direction."
This works beautifully for a few hundred paragraphs. But what about a million? Or a hundred million?
This is the scaling nightmare. A brute-force search, comparing your query vector to every single one of the 1,000,000 vectors in your dataset, is computationally expensive and too slow for any real-time application. You can't just for loop your way out of this one.
This is the problem that vector databases solve.
The High-Performance Index for Meaning
Vector databases are specialized data stores built for one job: finding the Approximate Nearest Neighbors (ANN) for a given vector, incredibly fast. They use clever indexing algorithms like HNSW (Hierarchical Navigable Small World) to build a searchable map of your vector space. Instead of checking every single point, they can efficiently navigate this map to find the closest matches without scanning the entire dataset.
The workflow becomes:
- Ingestion (One-time): Take your documents (blog posts, product descriptions, etc.), run them through an embedding model, and store the resulting vectors in a vector database like Chroma, Weaviate, or Pinecone. You also store a simple reference ID back to the original text.
- Query (Real-time): Take the user's search query, run it through the exact same embedding model to get a query vector.
- Search (Real-time): Pass that query vector to the database and ask, "Give me the top 5 vectors closest to this one."
- Retrieve (Real-time): The database returns the reference IDs of the most similar documents in milliseconds. You then use these IDs to fetch the original human-readable text from your primary database (like PostgreSQL or Firestore) to display to the user.
The vector database is a high-performance index, not the source of truth for your content. The intelligence is not in the database; it's baked into the vectors by the embedding model.
The Strategic Implications for Builders

Getting my head around the mechanics, I started thinking about the second-order effects. What does this actually change for someone building a product today?
1. A Game-Changer for Vernacular Content
Keyword search is a disaster for non-English languages, especially Indic languages. Transliterations (kaise vs kese), synonyms, and dialectical differences make string matching impossible. Semantic search blows past this. With an embedding model that understands Hindi, a user searching for "GST kaise file karein" can find a document that explains the "Goods and Services Tax filing process" in Hinglish. This unlocks massive amounts of content for Tier-2 and Tier-3 audiences. Every government portal, e-commerce site, and content platform needs this.
2. Your Moat Isn't Your Database, It's Your Data
Using Pinecone or Weaviate is not a competitive advantage. It's a commodity infrastructure choice. Your real, defensible moat is twofold:
- Your Proprietary Data: The unique, high-quality dataset you create embeddings from.
- Your Fine-Tuned Model: A generic model is good, but a model fine-tuned on your specific domain's language (e.g., Indian legal jargon, medical terminology, or even your company's internal documents) will be exponentially better. The startups that win will master the data and the models, not the managed database configuration.
3. Democratizing AI-Powered Features (with a Cost)
For years, building a good recommendation engine required a team of PhDs. Now, a single developer can spin up a ChromaDB instance, pull a model from Hugging Face, and build a powerful semantic search feature in a weekend. This radically lowers the barrier to entry. A small D2C brand on Shopify can now have product search that understands a user searching for "something comfortable to wear at home" and shows them cotton pajamas, even if those keywords aren't in the description.
The caveat is cost. Generating embeddings via paid APIs (like OpenAI or Cohere) and running a managed vector DB isn't free. The tension between a powerful-but-expensive proprietary model versus a good-enough-and-free open-source one will define the architecture of many early-stage products.
Photo by Isaac Smith on Unsplash
Building My Own Semantic Search: A Practical Guide
Theory is cheap. The only way to really learn is to build. My next step is to build the semantic search for my newsletter archive. I'm taking the simplest path possible to understand the end-to-end process.
The Tech Stack
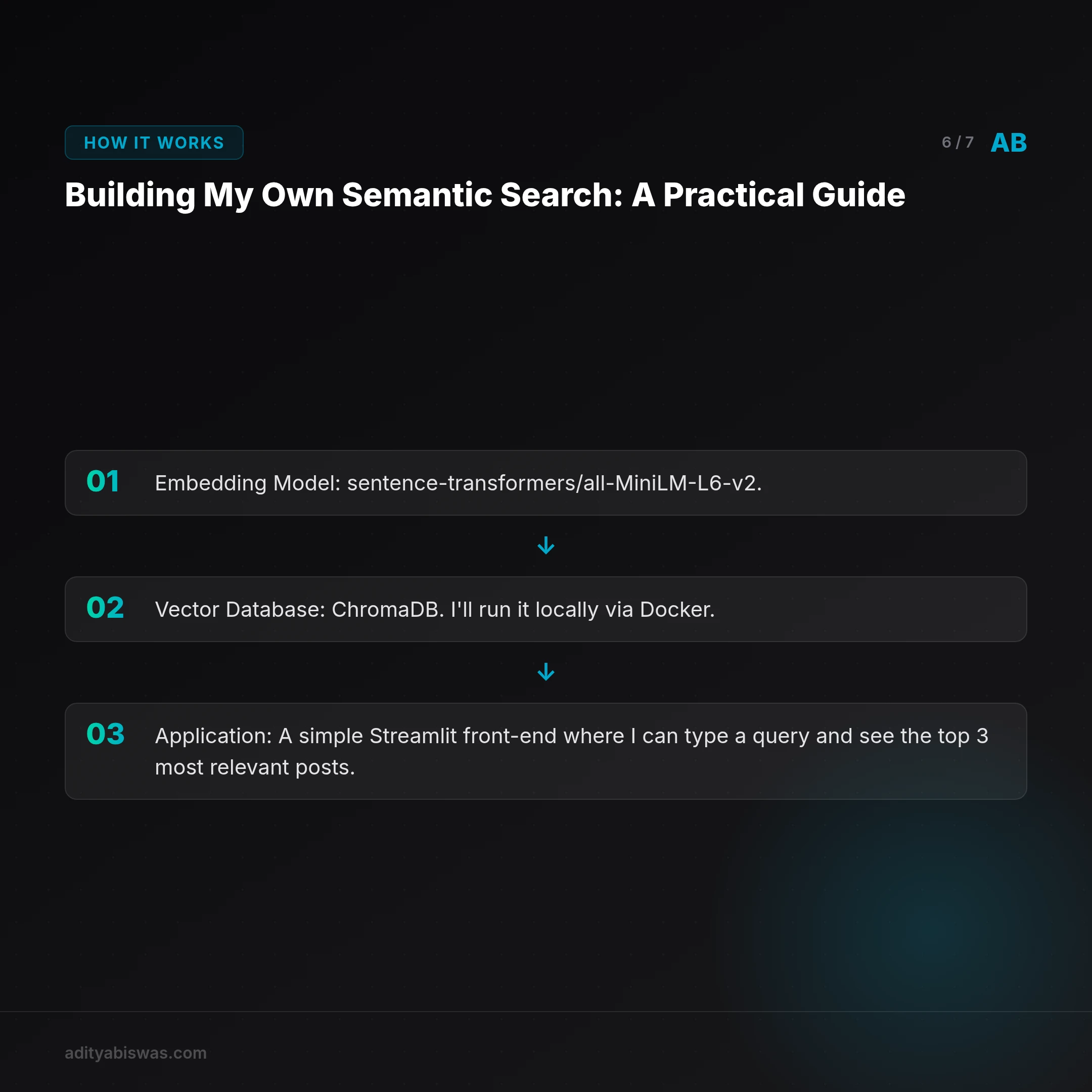
- Embedding Model:
sentence-transformers/all-MiniLM-L6-v2. It's open-source, runs on my laptop's CPU, and is excellent for English text. No API keys, no costs. - Vector Database:
ChromaDB. I'll run it locally via Docker. It's perfect for projects that don't need to scale to billions of vectors on day one. - Application: A simple
Streamlitfront-end where I can type a query and see the top 3 most relevant posts.
My goal is to document the process and answer the practical questions you only encounter by getting your hands dirty: What's the best way to chunk documents before embedding, by sentence, by paragraph? How good is the out-of-the-box model? What kind of queries fail?
From here, the path forward is clear: moving from generic models to fine-tuned, domain-specific intelligence. But first, you have to make the damn thing work. I'll report back.
Frequently Asked Questions

What's the difference between a vector database and a regular database like PostgreSQL?
A regular database is optimized for storing and filtering structured data based on exact matches (e.g., WHERE user_id = 123). A vector database is optimized for a single task: finding the most similar items to a given data point in a high-dimensional space. While some regular databases like PostgreSQL are adding vector search capabilities (with extensions like pgvector), dedicated vector databases are often more performant at massive scale.
Do I need a GPU to work with embeddings?
It depends. For inference (generating embeddings for a query or a small batch of documents), a CPU is often sufficient, especially with smaller, optimized models like all-MiniLM-L6-v2. For training or fine-tuning an embedding model on a large dataset, a GPU is practically a requirement.
Can I use embeddings for more than just text search?
Absolutely. Embeddings are a way to represent any data type as a vector. You can create embeddings for images (to find visually similar products), audio (for music recommendation), and even user behavior. If you can represent it as a vector, you can build a similarity search for it.
Related Reading
- Claw Learns: Why Probabilistic AI Loops are Dead for Indian SaaS, Stop letting your agents wander. In 2026, the real money in Indian vertical SaaS is built on deterministic state machines and Google ADK. Claw shares why...
- The Nvidia Tax is Ending: Why OpenAI Just Swallowed TBPN, OpenAI's acquisition of TBPN isn't about talent; it's a brutalist move to verticalize their stack and kill the "Nvidia Tax" for good.
